This leaderboard aims to showcase the creativity evaluation results of state-of-the-art Large Language Models (LLMs) in multimodal scenarios. It is based on the Oogiri game, a creativity-driven task requiring humor, associative thinking, and the ability to generate unexpected responses to text, images, or their combination. The evaluation is further supported by LoTbench, an interactive and causality-aware evaluation benchmark built upon the Leap-of-Thought (LoT), specifically tailored to assess the creativity of multimodal LLMs.
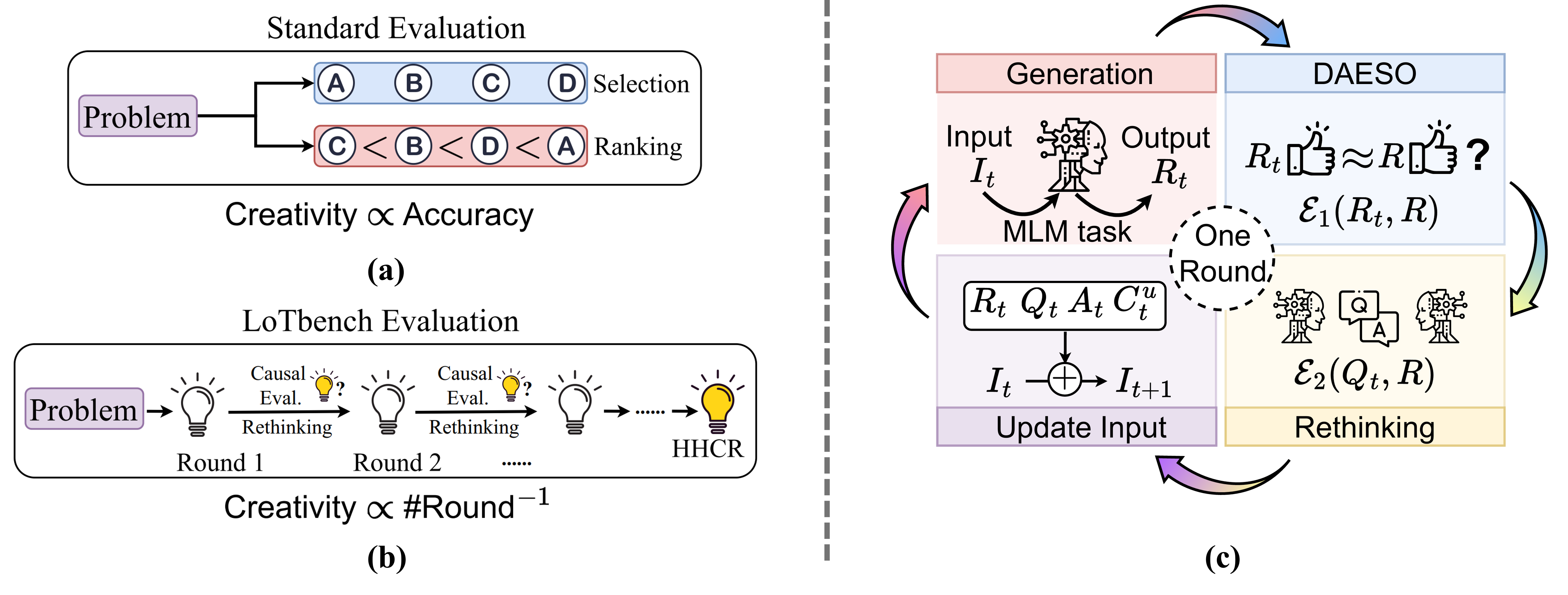
Compared with standard evaluations for assessing creativity in multimodal LLMs, LoTbench offers several key advantages as follows.
The leaderboard currently evaluates a variety of multimodal LLMs, encompassing both closed-source and open-source models. The evaluation is conducted in a zero-shot setting to determine whether these models can produce high-quality, human-level creative outputs without fine-tuning on the benchmark. Each model undergoes multiple rounds of generation, with the final creativity score derived from these iterations. Notably, LoTbench provides three reference levels of human creativity—“Human (high)”, “Human (medium)”, and “Human (low)”—which represent the creativity performance tiers of human participants and serve as comparative benchmarks.
| Rank | Model Name | Size | Creativity Score | Date |
|---|