Recently, numerous benchmarks have been developed to evaluate the logical reasoning abilities of large language models (LLMs). However, assessing the equally important creative capabilities of LLMs is challenging due to the subjective, diverse, and data-scarce nature of creativity, especially in multimodal scenarios. In this paper, we consider the comprehensive pipeline for evaluating the creativity of multimodal LLMs, with a focus on suitable evaluation platforms and methodologies. First, we find the Oogiri game—a creativity-driven task requiring humor, associative thinking, and the ability to produce unexpected responses to text, images, or both. This game aligns well with the input-output structure of modern multimodal LLMs and benefits from a rich repository of high-quality, human-annotated creative responses, making it an ideal platform for studying LLM creativity. Next, beyond using the Oogiri game for standard evaluations like ranking and selection, we propose LoTbench, an interactive, causality-aware evaluation framework, to further address some intrinsic risks in standard evaluations, such as information leakage and limited interpretability. The proposed LoTbench not only quantifies LLM creativity more effectively but also visualizes the underlying creative thought processes. Our results show that while most LLMs exhibit constrained creativity, the performance gap between LLMs and humans is not insurmountable. Furthermore, we observe a strong correlation between results from the multimodal cognition benchmark MMMU and LoTbench, but only a weak connection with traditional creativity metrics. This suggests that LoTbench better aligns with human cognitive theories, highlighting cognition as a critical foundation in the early stages of creativity and enabling the bridging of diverse concepts.
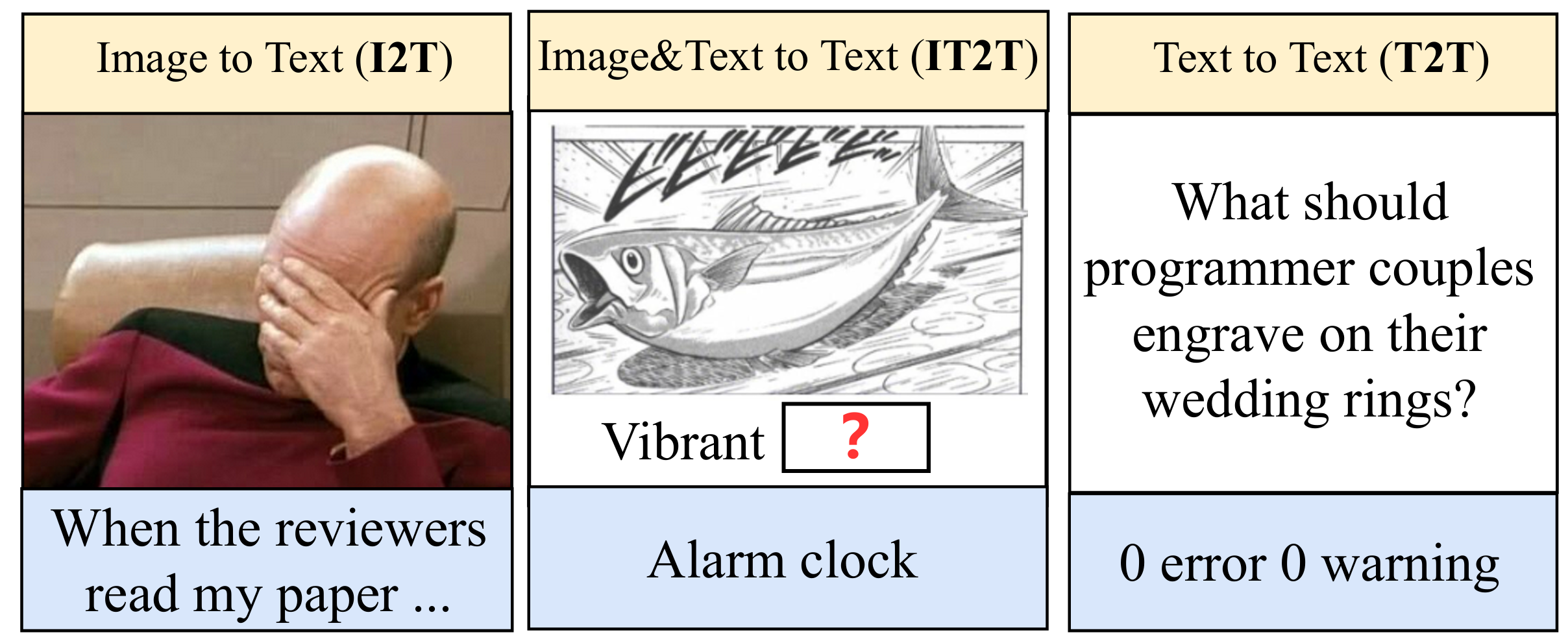
Oogiri game: Thoroughly assessing LoT is challenging due to the complexity of measuring creative thinking and the difficulty in gathering pertinent data, since generating novel ideas is challenging, even for humans. Given these constraints, we propose studying LoT in MLLMs through the lens of Oogiri-style humor generation. Oogiri, a traditional Japanese creative game, requires participants to provide unexpected and humorous responses to prompts in the form of images, text, or a combination of both. This game challenges MLLMs to demonstrate a sudden burst of insight and strong associative thinking, presenting a unique challenge for CoT-based methods. Moreover, the Oogiri game aligns with the input-output paradigm of current MLLMs and, due to its popularity, offers a wealth of high-quality, human-annotated creative responses, making it an ideal platform for exploring LoT ability of MLLMs. Moreover, to investigate the LoT ability of LLMs in the Oogiri game, we initially present the multilingual and multimodal Oogiri-GO dataset which comprises more than 130,000 high-quality Oogiri samples in English, Chinese, and Japanese, and curated to prompt textual humor in response to inputs that can be images, text, or both.
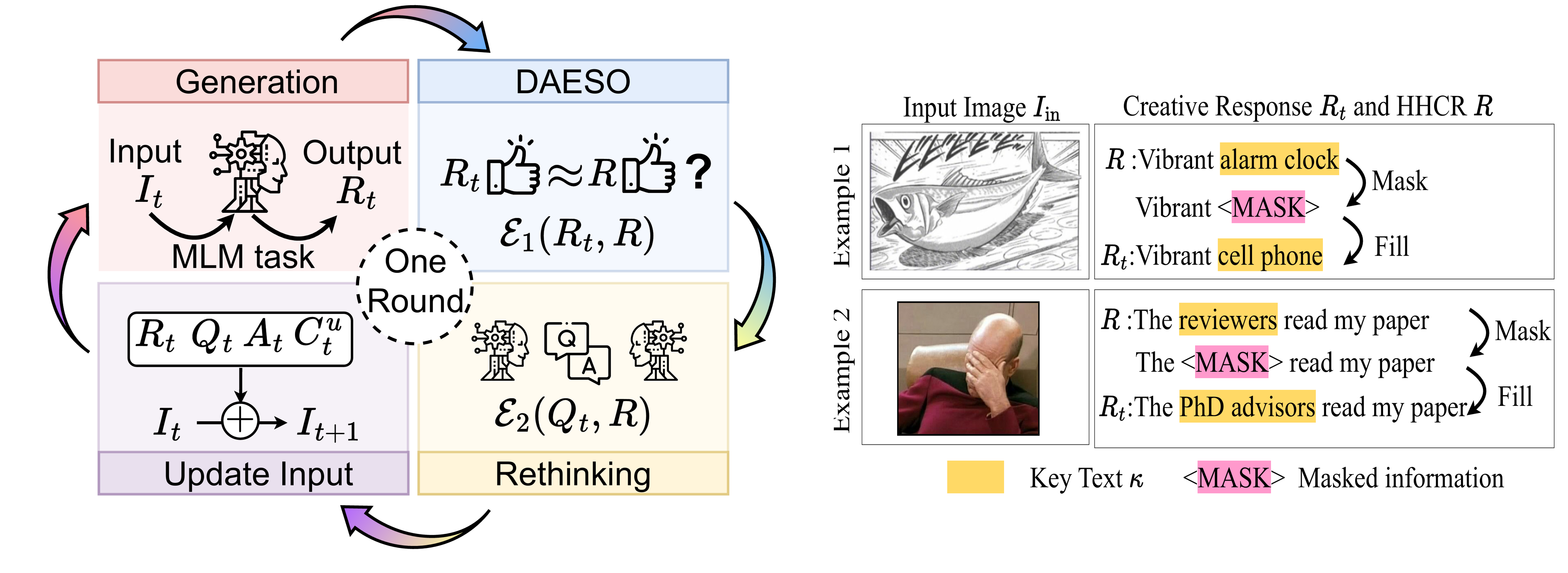
LoTbench: First, following the popular standard LLM benchmark paradigm, we also establish a series of standard LLM evaluations by Oogiri-GO, such as ranking and selection, with higher accuracy indicating greater creativity. We find that even advanced LLMs and reasoning frameworks, including GPT-4 and CoT, despite their exceptional reasoning capabilities and extensive prior knowledge of various forms of humor, still struggle to demonstrate adequate LoT ability for creative humor generation. Moreover, while standard evaluations offer simplicity and low assessment costs, we identify inherent risks associated with their use in assessing creativity, such as information leakage and limited interpretability. To address these issues, we first propose training LLMs to assist in generating specific high-quality human-level creative responses (HHCRs). Additionally, we introduce a multi-round interactive evaluation paradigm, LoTbench. With causal reasoning techniques, LoTbench measures creativity by analyzing the average number of rounds required for an LLM to reach HHCRs. Fewer required rounds indicate higher human-level creativity. LoTbench not only effectively evaluates LLM creativity but also provides interpretable visualizations of the LLM’s innovative thought process during interactions.

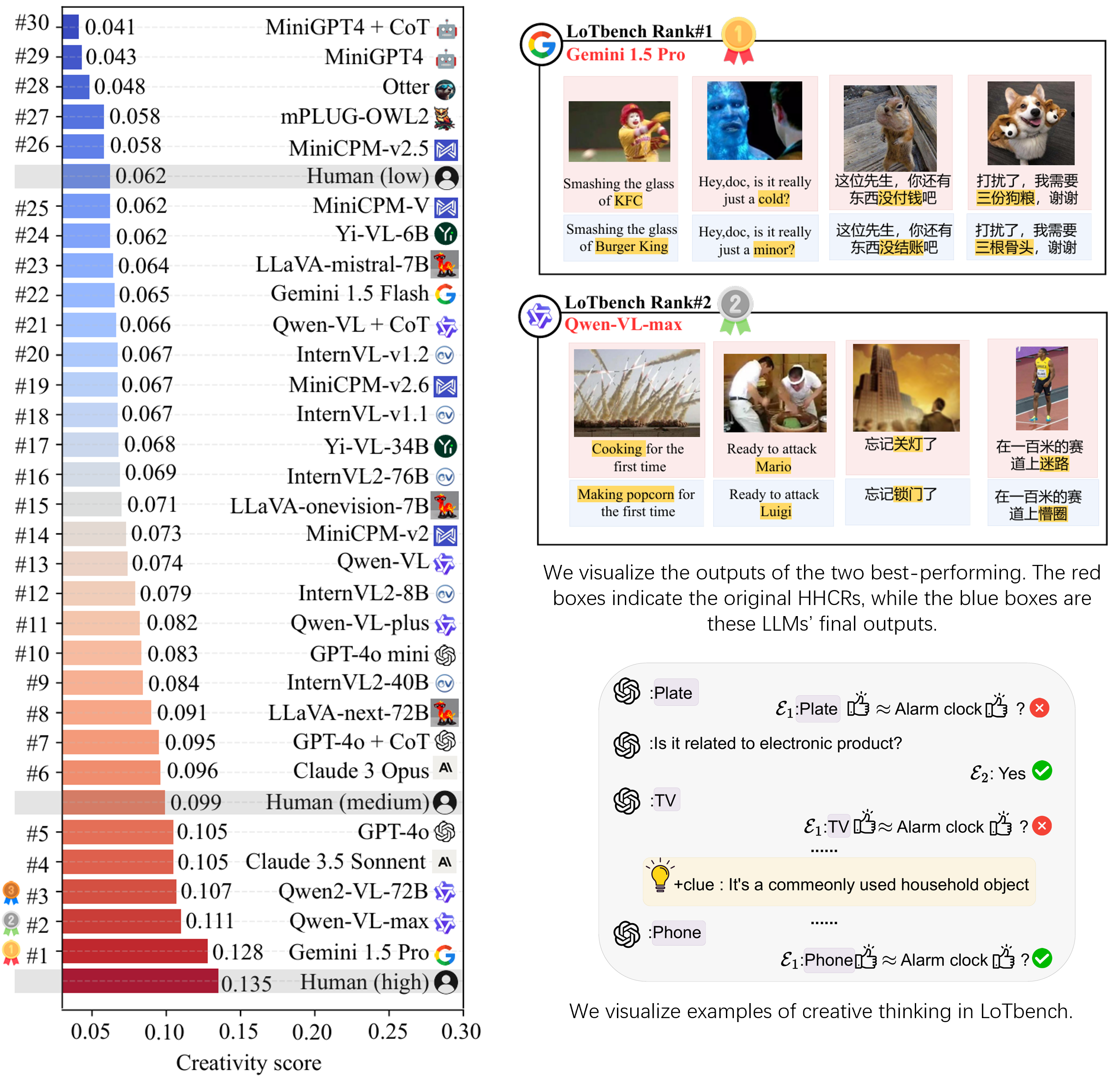
In this work, we assess the creativity of various multimodal LLMs using LoTbench. The results of LoTbench demonstrate that while most MLLMs exhibit limited creativity, the gap between their creativity and human creativity is not substantial. Current MLLMs show the potential to surpass human creativity. Furthermore, we observe a strong positive correlation between the results of the well-known multimodal LLM cognition benchmark MMMU and LoTbench, but a low correlation with standard creativity evaluation.
This indicates that LoTbench’s creativity measurements align more closely with human cognitive theories, suggesting that cognition serves as a critical foundation in the early stages of creativity, enabling leaps across diverse conceptual spaces.
@article{lotbench,
title={A Causality-aware Paradigm for Evaluating Creativity of Multimodal Large Language Models},
author={Huang Zhongzhan and Zhong Shanshan and Zhou Pan and Gao Shanghua and Zitnik Marinka and Lin Liang},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year={2025},
publisher={IEEE}
}